cs224n
Intro
本篇是对Stanford CS 224N | Natural Language Processing with Deep Learning (Spring 2024)这门课程的学习笔记。关于这门课的内容,总结如下:
- 词向量、RNN、LSTM、Seq2Seq 模型、机器翻译、注意力机制、Transformer 等等
What is this course about?
Natural language processing (NLP) or computational linguistics is one of the most important technologies of the information age. Applications of NLP are everywhere because people communicate almost everything in language: web search, advertising, emails, customer service, language translation, virtual agents, medical reports, politics, etc. In the 2010s, deep learning (or neural network) approaches obtained very high performance across many different NLP tasks, using single end-to-end neural models that did not require traditional, task-specific feature engineering. In the 2020s amazing further progress was made through the scaling of Large Language Models, such as ChatGPT. In this course, students will gain a thorough introduction to both the basics of Deep Learning for NLP and the latest cutting-edge research on Large Language Models (LLMs). Through lectures, assignments and a final project, students will learn the necessary skills to design, implement, and understand their own neural network models, using the Pytorch framework.
Word Vectors
$ vector(”King”)- vector(”Man”) + vector(”Woman”) $ results in a vector that is closest to the vector representation of the word Queen
How do we have usable meaning in a computer?
Slides里介绍了几种方式:
- WordNet
- one-hot vectors
- word vectors
那么前两种都有其现实意义,但也有明显的弊端。
-
WordNet,完全靠
synonum sets和hypernyms sets来确定词汇间的关系、构造复杂、无法及时吸收新词汇… -
one-hot vectors给每个词都设置了
symbol,尽管是用数字表达,但是相近的词之间在数学上没有联系(向量的点积为0)
那么下面就引出了一句名言:“You shall know a word by the company it keeps”
以及word vectors的思想,将词汇归一化到一个向量中,虽然每个词汇有多个词义,但其分布却近似是其多个词义的平均,并用点积来确定词向量间的相关性。
Word2vec
Word2vec很好地反映了word vectors的思想,计算中心词和相邻词的相似度,确定其概率分布:
- We have a large corpus (“body”) of text: a long list of words
- Every word in a fixed vocabulary is represented by a vector
- Go through each position t in the text, which has a center word c and context (“outside”) words o
- Use the similarity of the word vectors for c and o to calculate the probability of o given c (or vice versa)
- Keep adjusting the word vectors to maximize this probability
Objective Function
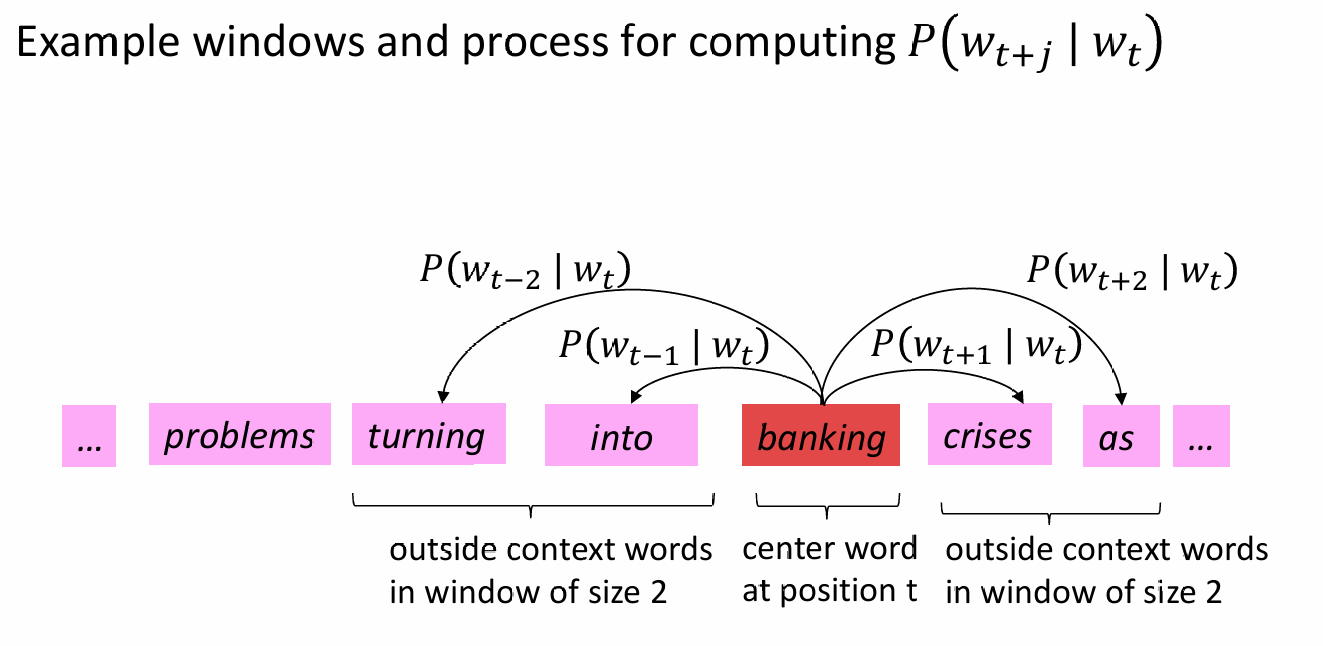
那么如何计算其似然程度(Likelihood)呢,For each position = , predict context words within a window of fixed size , given center word . Data likelihood :
为减小数据复杂程度,及方便计算机处理,优化上公式,对其进行平均负对数似然操作,The objective function is the (average) negative log likelihood:
最小化 等价于 最大化预测准确率。
Prediction Function
- : 点积越大,代表这两个词在向量空间中的位置越接近,即语义相关性越高。
Dot product compares similarity of o and c. Larger dot product = larger probability. - : 将任何实数映射为正数。由于指数函数的增长特性,它会放大较大点积的影响,使相关性高的词获得更高的权重。
- : 分母是对词汇表中所有可能的词进行求和。这一步确保了所有可能输出的概率之和等于 1,从而构成一个标准的概率分布。
这也是对Softmax Function的应用
- Softmax 函数将任意值 映射为一个概率分布 。
- “max”:因为它会放大最大值 对应的概率,使大的更大。
- “soft”:因为它仍然会给较小的 分配一些概率。
To Train the Model
To train a model, we gradually adjust parameters to minimize a loss.
-
如果词向量维度为 ,词汇量为 ,则总参数量为 。
-
每个单词有两个向量, 包含了词汇表中所有单词的两种向量表示(中心词向量 和背景词向量 )。
-
计算所有参数的梯度,以优化模型
梯度公式就是对Softmax Function的求偏导,数学过程如下:
-
初始损失函数 (单词对的负对数似然)
这是针对一个中心词 和一个背景词 的基本损失定义: -
代入Softmax定义展开
将 的公式代入,利用对数性质将除法化为减法: -
第一部分求导
对点积项关于中心词向量 求偏导: -
第二部分求导
利用链式法则对 形式进行求导: -
转化为概率期望形式
将上一步的结果重新组合,提取出原始的概率项 : -
最终梯度公式
将两部分合并,得到最终用于更新 的梯度:
Gradient Descent
梯度下降更新方程 (矩阵形式)
梯度下降更新方程 (单个参数形式)
- (alpha): 步长或学习率(step size / learning rate)。
但是实际应用并非上面的方法,而是用随机梯度下降,(Stochastic Gradient Descent, SGD)
- 目标函数 是语料库中所有窗口的函数。如果每次更新都要计算整个语料库的梯度 ,计算成本极其昂贵,在进行单次更新前需要等待极长时间。
- SGD不再计算整个语料库,而是通过重复采样窗口,每处理一个(或一小批)窗口就更新一次参数。
Skip-gram Model with Negative Sampling
采用最传统的方法计算概率时,即softmax,它的分母是全部词的叠加,计算量太大
而Skip-gram Model with Negative Sampling不需计算所有可能的词,而是训练一些逻辑回归,更偏好实际的上下文而非随机的上下文,实际上会选K个负样本,计算量就变为了
其中,即sigmoid函数,使符合的结果概率接近于1,而不符合的则接近于0
但这又会导致低频词,如"zebra"的概率过低,而像"the"这样的词则概率较高,所以给公式加上次方:
来提高低频词的概率。
GloVe
original GloVe papar (Global Vectors for Word Representation)
Co-occurrence Martix
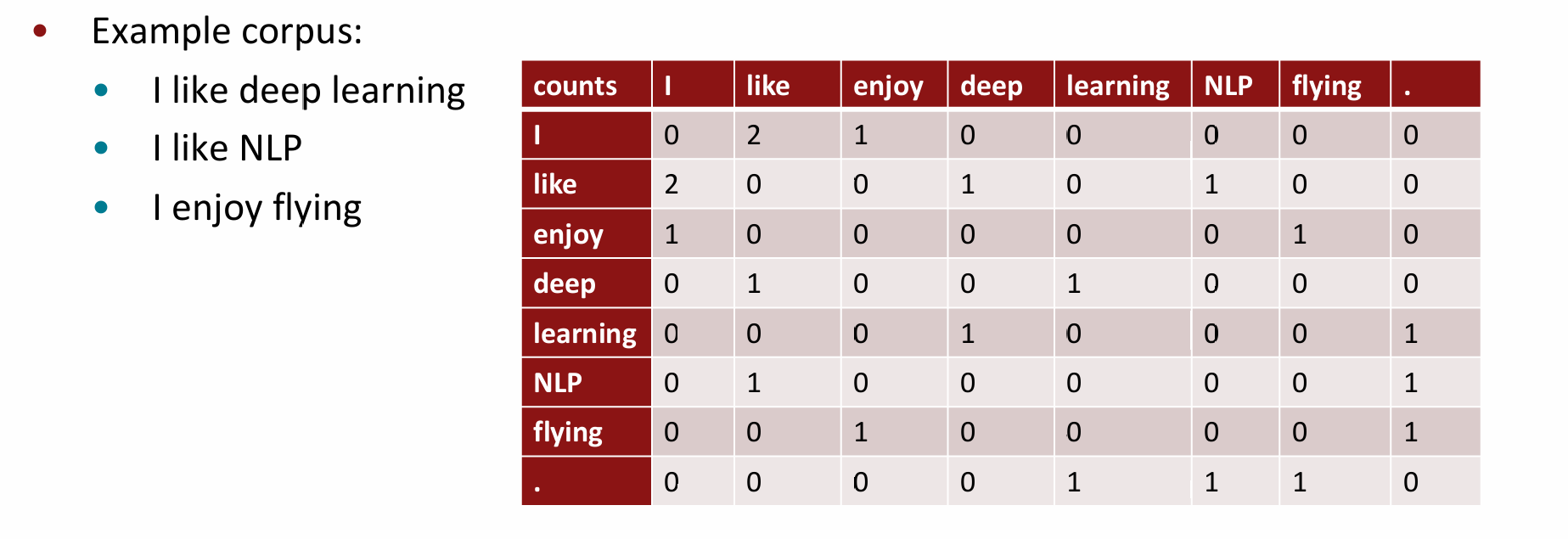
构建共现矩阵的方法非常简单,首先设定窗口长度,然后对在窗口长度内出现的共现词频率进行计数,一个简单的例子如上图(窗口为1,仅算相邻词)。但是:
- 词向量维度会随着语料库中词汇的增多而大幅增加,这会导致所需存储空间增大,且矩阵会变得相当稀疏,基于此构建的模型鲁棒性较差;
- 功能词出现频次极高,但没有提供相应的信息;
- 没有反映出词距与词相关性之间的联系。
那么如何进行降维来优化?经典的方法是进行SVD矩阵分解(虽然问了AI也没明白原理,而且Assignment1中用一个sklearn的函数就解决了)
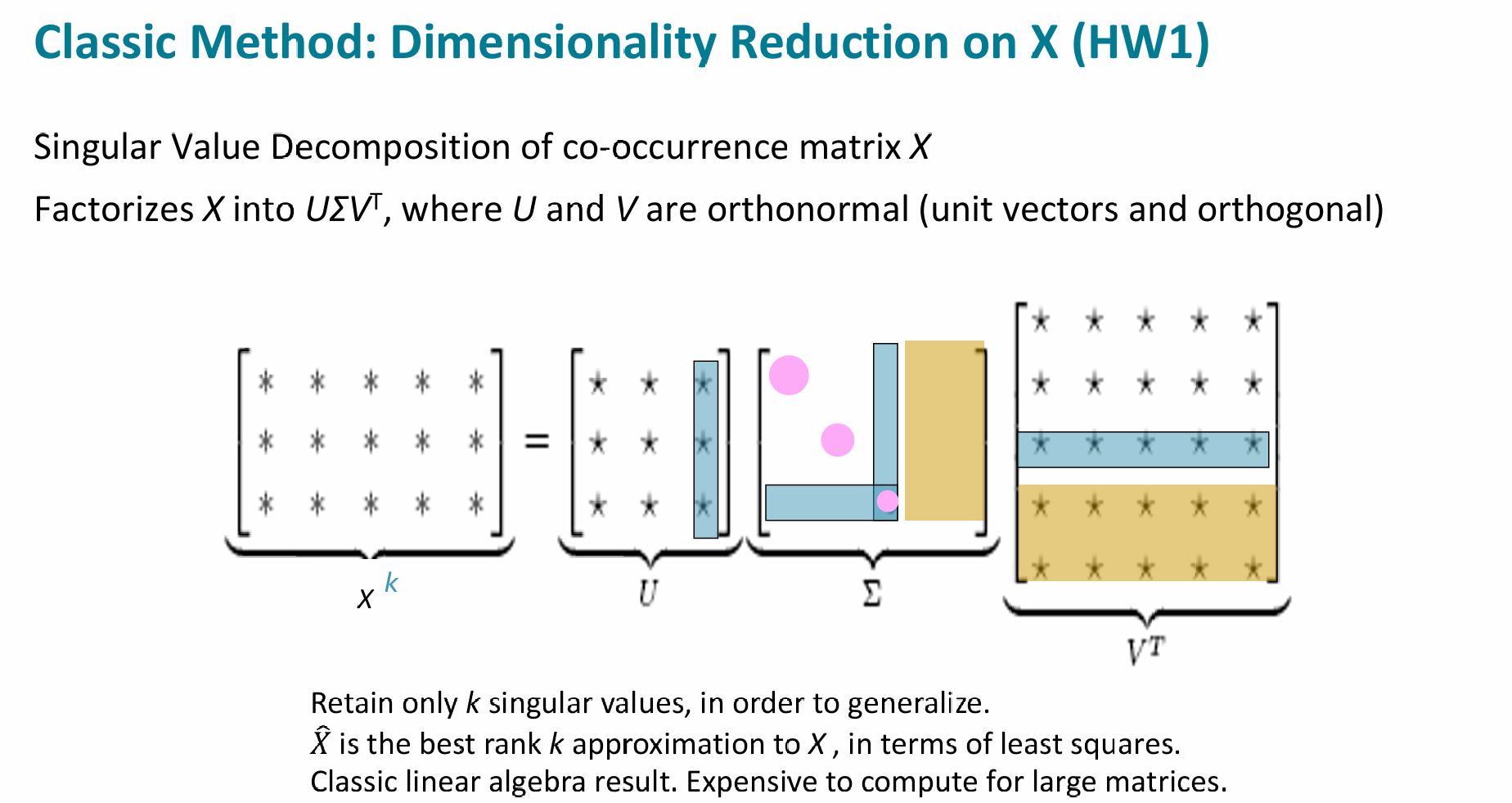
- (共现矩阵):大小为 (词表大小)。每个元素 代表词 和词 在语料库中共同出现的次数。
- 和 (正交矩阵):它们的列向量是相互正交的单位向量(Orthonormal)。在 NLP 中, 的每一行通常被视为该词的原始“嵌入”。
- (对角矩阵):对角线上的值 称为奇异值。它们按从大到小排列,代表了数据在对应维度上的重要程度(方差/信息量)。
那么降维便是将从共现矩阵得到的的,长度为的词向量降维成长度为的向量
真正编码语义的不是共现概率本身,而是共现概率的比值:
共现概率的比率可以编码语义成分,我们希望将它们作为线性语义成分捕捉在词向量空间中!
Analogies
词向量虽然数学原理上很强大,但是其实际的类比(Analogy)场景却是有不少问题:
下例可见,是一个的问题,那么显而易见且最有可能的结果就是grandmother,那么为何程序给出的另外几个,如granddaughter, mother之类,score也几乎一样很高呢?
# Run this cell to answer the analogy -- man : grandfather :: woman : x |
[('grandmother', 0.7608445286750793), |
虽说Assignment里没有标准答案,但是通过AI可以得知:这涉及到“语义聚类”
- 语义的“近邻效应”
- 在向量空间中,逻辑相似的词通常会聚在一起形成一个“簇”。当你计算出 时,你实际上是在空间中定位了一个坐标点。
granddaughter等同样具有“女性”和“亲属”属性,且在语料库中经常与grandfather或grandmother出现在相似的上下文。在向量维度上,它们在“亲属关系”这个维度上非常接近。
- 维度的“重叠性”
- 词向量通常有几百个维度。虽然我们减去了
man并加上了grandfather,但这并不能完全抹除其他维度的相似性。 daughter、mother、grandmother共享了绝大部分维度:[+女性]、[+人类]、[+亲属]。
- 词向量通常有几百个维度。虽然我们减去了
下面的例子,属于"Incorrect Analogy",我们来看易得答案为socks,但为何模型忽略了glove和hand,而输出了各种square的名词?显然和foot“脚”的释义无关,而是“英尺”的释义。
pprint.pprint(wv_from_bin.most_similar(positive=['foot', 'glove'], negative=['hand'])) |
[('45,000-square', 0.4922032654285431), |
- 语义多义性的干扰
- 上面也提到,
foot也是计量单位”英尺“的英文,和square组合是合理的
- 上面也提到,
- 训练语料的偏见
- 既然
foot有多个释义,但输出却全是其“英尺”的意思,那么这可能体现了用来训练的语料中多是...square和foot相关联
- 既然
- 词的选择
- 即使输出全是
...square,其score值也不过0.5,这不仅说明模型找不到强相关的词,而且说明了模型很可能没能理解glove与hand, foot的联系
- 即使输出全是
Neural Network
A neural network = running several logistic regressions at the same time.
CS231n Deep Learning on Network Architectures
CS231n Deep Learning for Computer Vision on Backprop
Structure
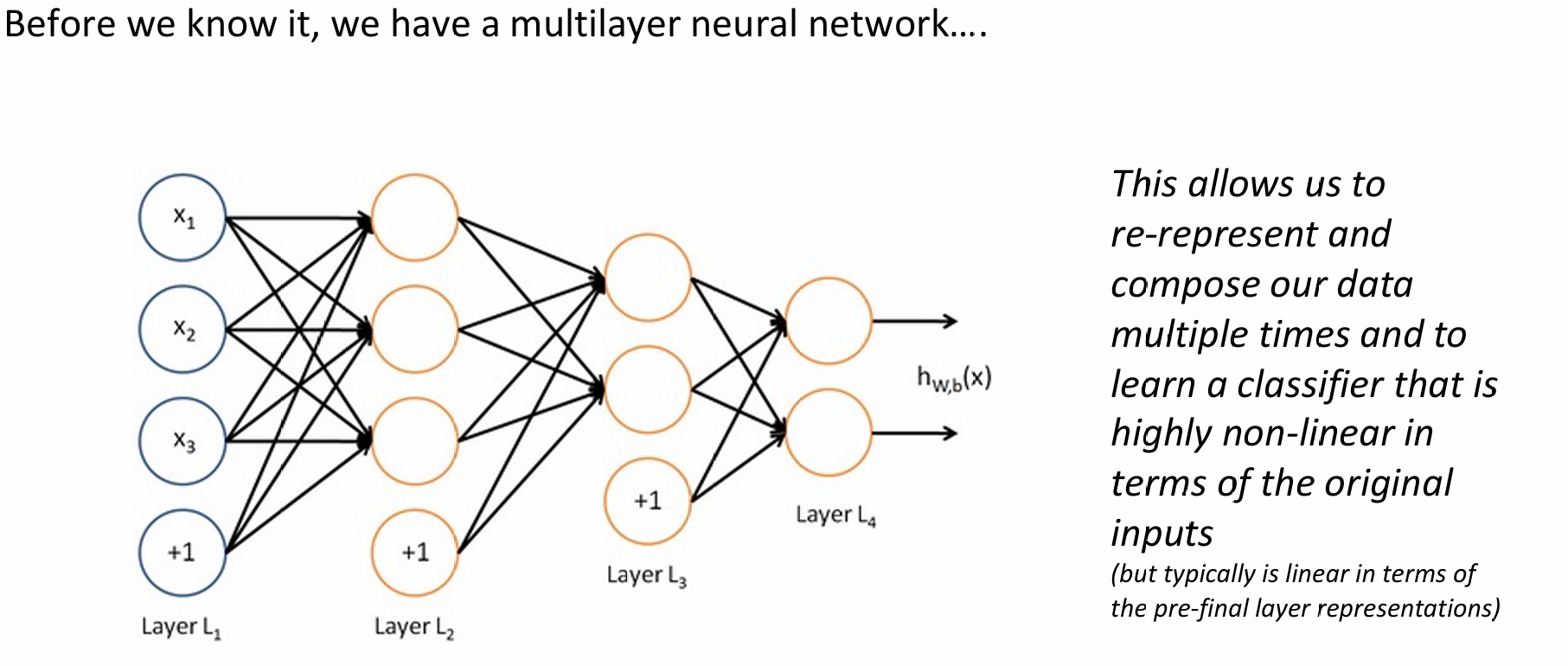
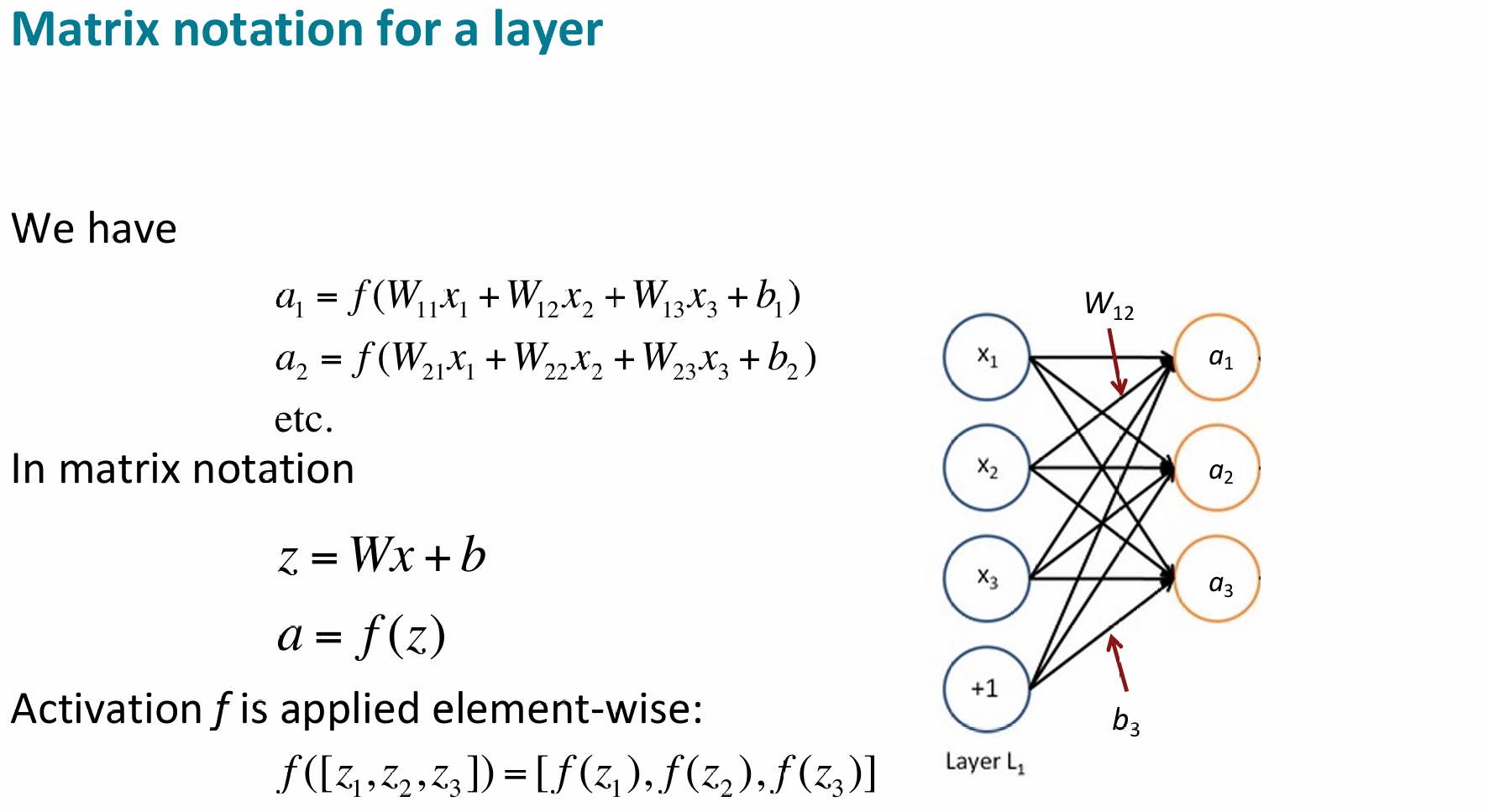
Non-linearities
为什么神经网络需要非线性(Non-linearities)?
- 核心观点:神经网络执行函数逼近,例如回归或分类。
- 没有非线性:深度神经网络只能执行线性变换。
- 多层失效:额外的层会被压缩成单个线性变换:(即多层线性层等同于一层)。
- 有了非线性:通过包含非线性的多层结构,网络可以逼近更复杂的函数!
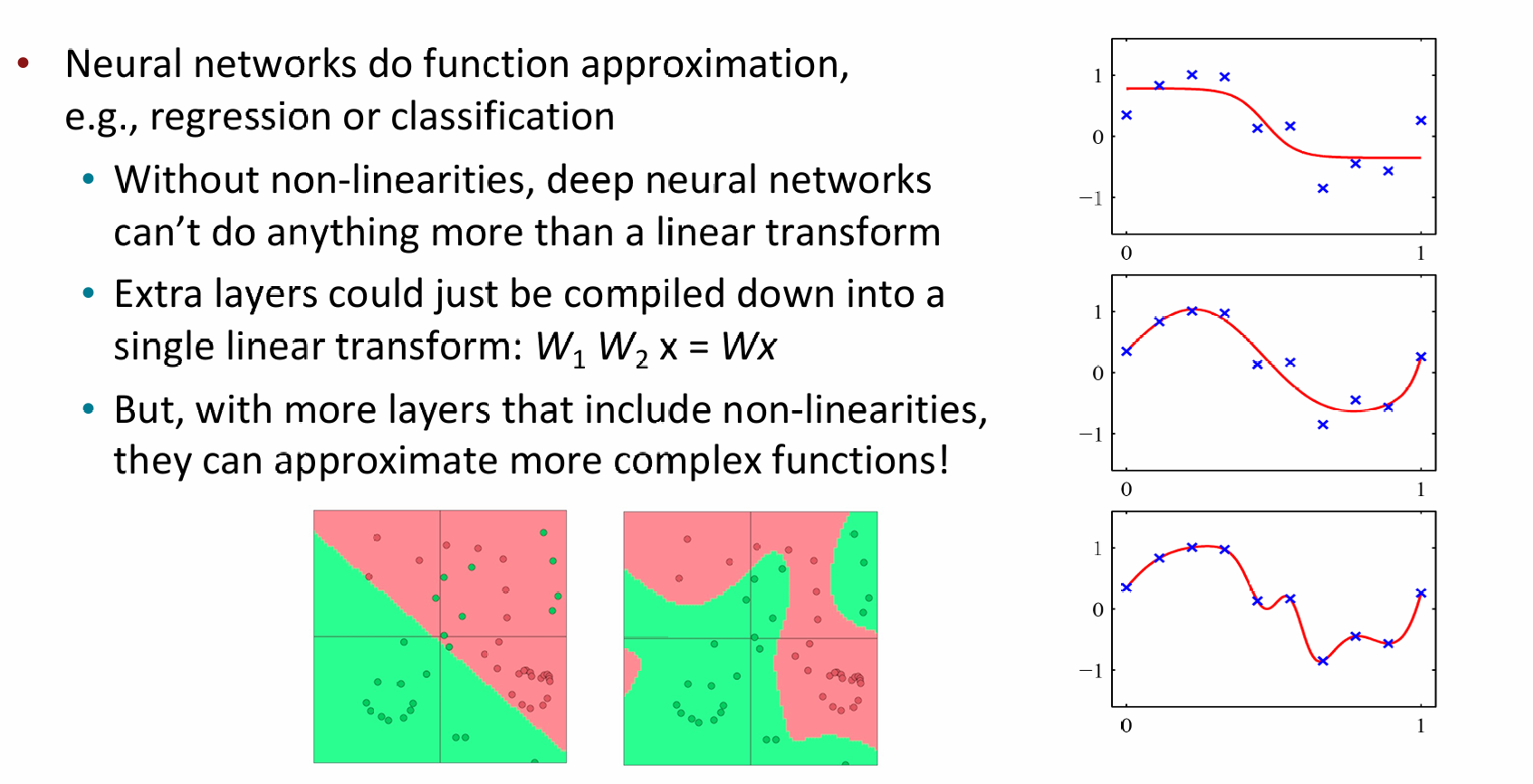
- 左下侧图对:左图显示线性分类(只能画直线),无法区分复杂的红绿点分布;右图显示非线性分类(可以画曲线),完美分割了数据。
- 右侧三张波形图:展示了随着函数复杂度的增加,只有非线性模型才能拟合这些起伏的蓝点(观测数据)。
关于常用的非线性函数,在《智能计算系统》课上均有学习,不多赘述
Gradients
梯度,简单地讲就是对变量的微积分,比如我们有:
那么它的梯度就是:
当然,这只是个非常简单的例子,实际上是大规模的链式法则计算,对矩阵(Jacabian Matrix)进行梯度计算。
Chain Rule
在单变量微积分中,如果 且 ,那么:
但在神经网络中,每一层都是一个向量 。当我们将这个逻辑扩展到向量时,乘法就变成了矩阵乘法。
对于多个变量,应与Jacobians矩阵相乘:
假设有 和 ,下面的这些偏导数就是雅可比矩阵
Matrix Calculus
由下式得,矩阵只有对角元素,其余部分均为0:
此外,还有一常有的Jacobian:
假设 和 都是 维列向量:
那么它们的内积(也就是括号里的部分)是一个标量:
我们要对向量 求导。根据 Jacobian Matrix 的定义,我们需要对 中的每一个元素 分别求导:
由于除了 这一项外,其他项都不包含 ,所以它们对 的导数都是 :
按照 Jacobian 矩阵的惯例,一个标量对一个列向量求导,结果是一个行向量:
Write out the Jacobians
= Hadamard product = element-wise multiplication of 2 vectors to give vector
| 变量 | 神经网络中的含义 | 说明 |
|---|---|---|
| 损失函数值 (Loss/Score) | 最终的标量输出(例如交叉熵损失)。我们要看它随参数如何变化。 | |
| 偏置向量 (Bias) | 当前层的偏置项,神经网络需要学习的参数之一。 | |
| 净输入 (Logits/Pre-activation) | 线性组合后的结果,即 。 | |
| 激活值 (Activation/Hidden state) | 经过非线性激活函数后的输出,即 。 | |
| 上游传回的梯度 () | 损失函数对当前层输出的导数,它是从更高层“反向传播”回来的信号。 | |
| 激活函数的导数 | 比如 ReLU 或 Sigmoid 的导数。它决定了哪些神经元处于活跃状态。 | |
| 单位矩阵 (Identity Matrix) | 因为 , 对 求导的结果是 1(矩阵形式即为单位阵)。 |
Re-using Computation
误差信号(Upstream Gradient):
我们先算出这个值 ,可以简化计算:
-
对权重矩阵 的梯度展开:
-
对偏置向量 的梯度简化:
Shape Convention
假设权重 ,输出是一个标量 (损失)。按纯数学定义, 应该是一个 的行向量(Jacobian)。但如果使用这种形式,梯度更新公式 就会因维度不匹配而无法直接相减。
为了计算方便,我们约定梯度的形状必须等于参数的形状。因此 也是一个 的矩阵:
那么我们究竟应该以什么样的“形状”来呈现导数结果?
采取始终遵循**形状约定 (Shape Convention)**的方式:
- 做法:不拘泥于严格的 Jacobian 定义,而是时刻盯着变量的维度(Dimensions)。
- 核心技巧:通过观察维度来决定何时需要对某个项进行转置,或者调整矩阵相乘的顺序,以确保每一层算出来的梯度形状和该层的参数形状完全一致。
- 关于 的重要结论:传导至隐层(Hidden layer)的误差信号 ,其维度应该与该隐层的神经元数量(即激活值向量的维度)完全相同。
Backpropagation
按流程逐步计算各函数,从输入得到输出,即是正向传播(Forward Propagation)
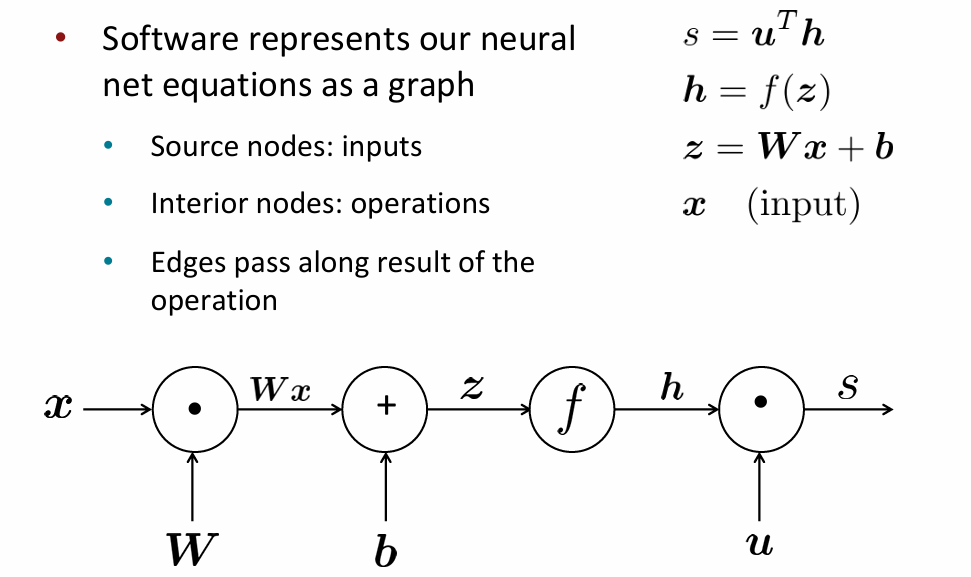
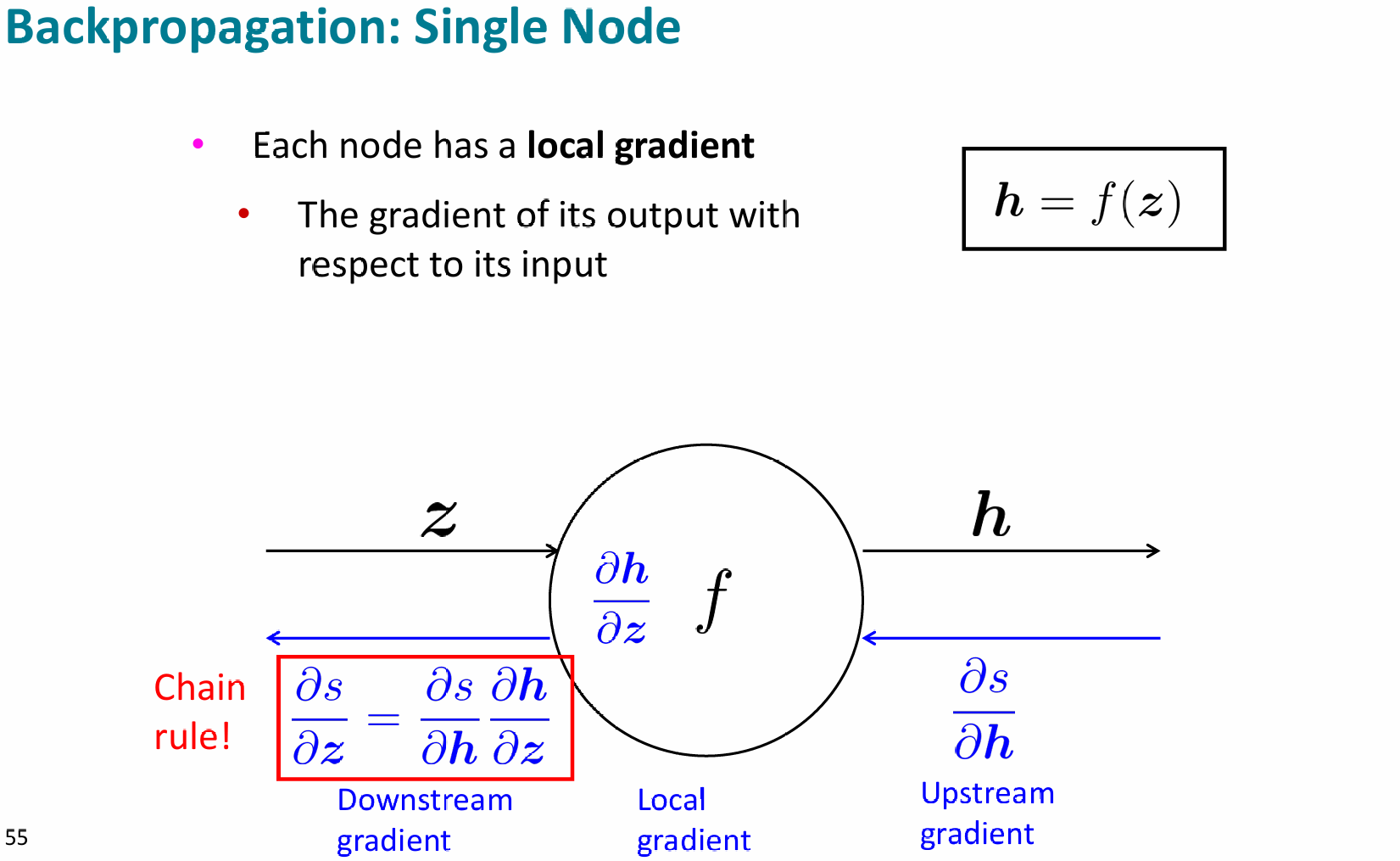
对于反向传播中的单个节点,有
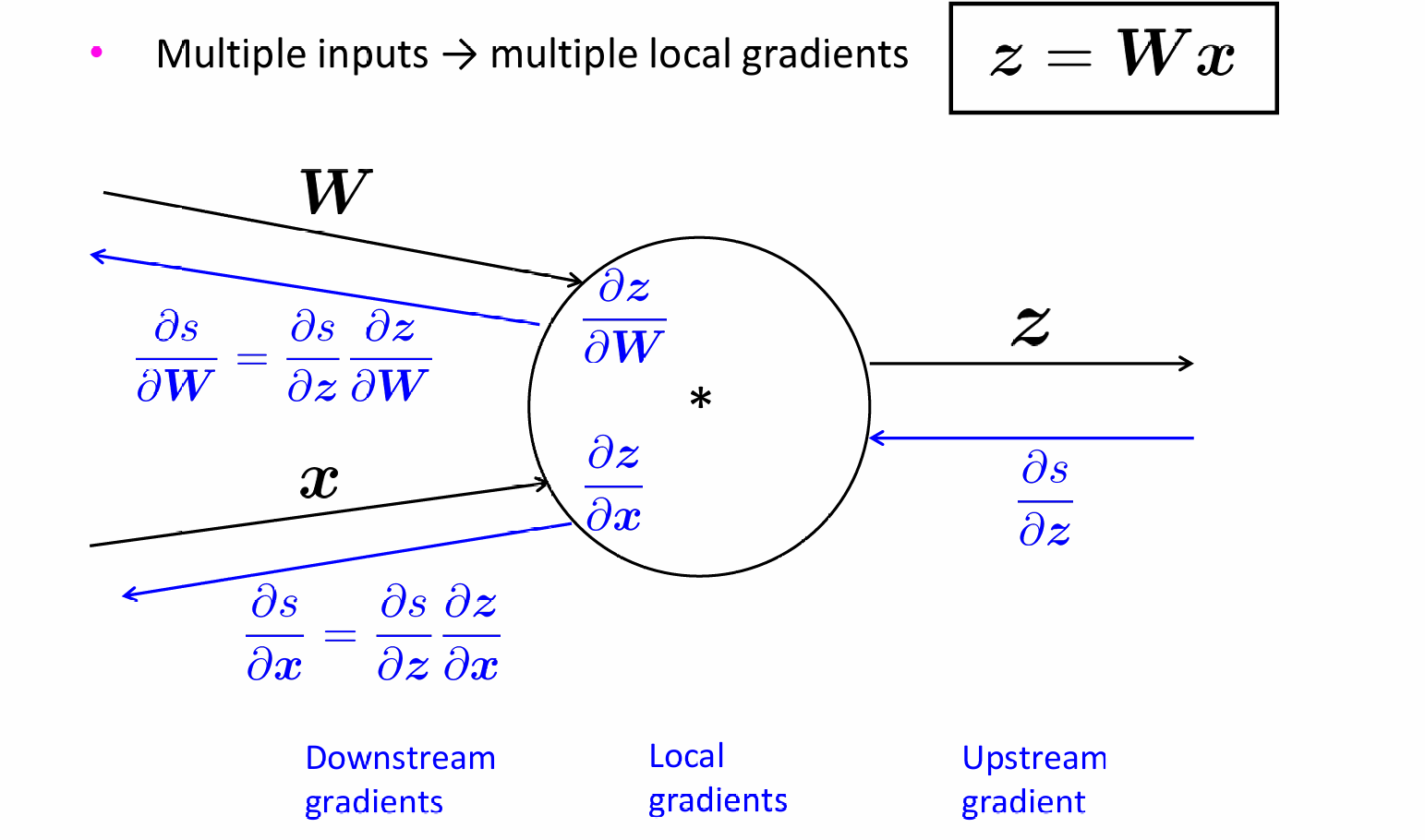
对于单节点的多输入,upstream gradient不变,各输入的local gradient不同,但计算公式是不变的
下面举个多输入的实际例子
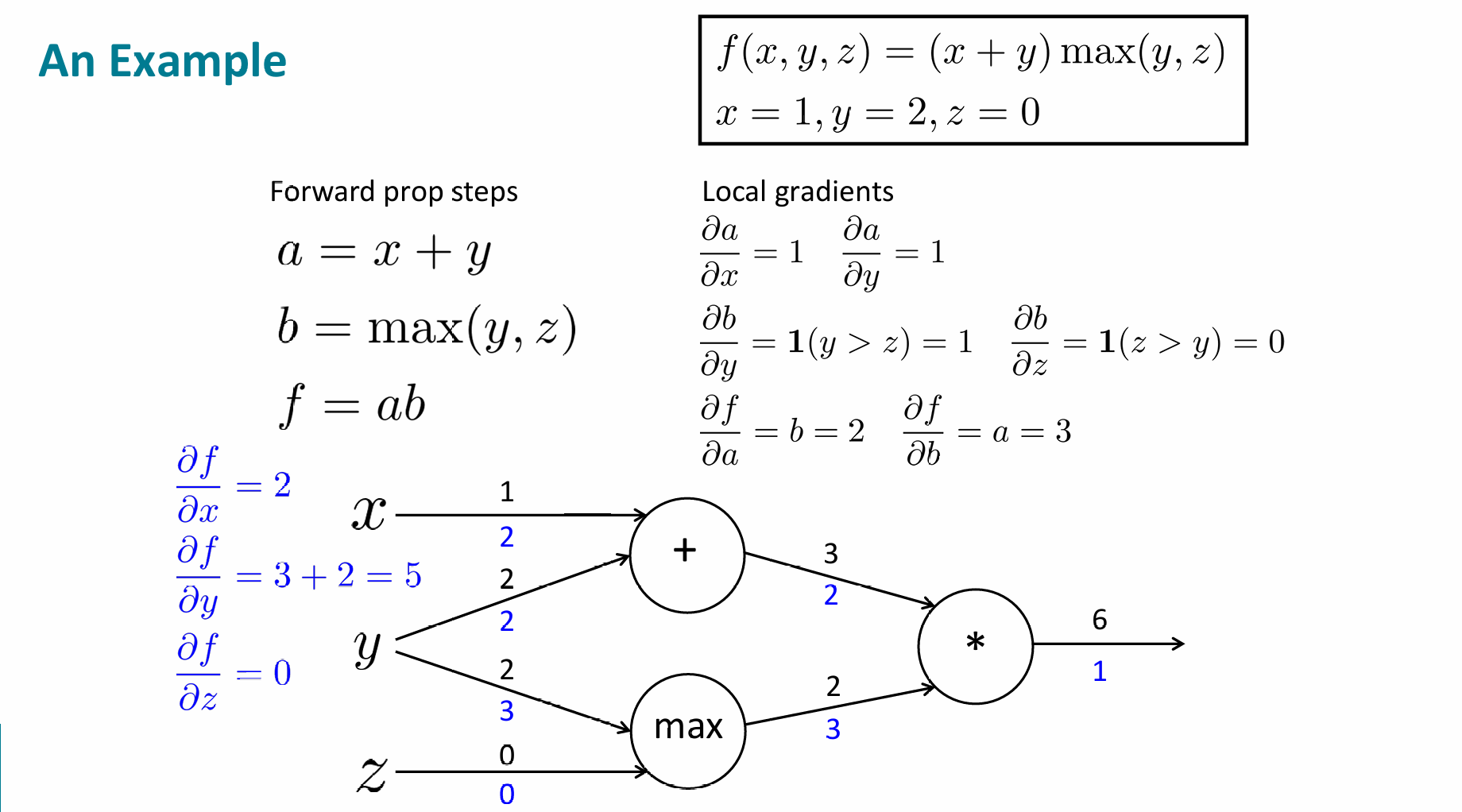
我们可以在这个基础上,假设输入y的值变为了2.1,那么,,
所以,y值变化的0.1导致了结果0.51的变化,那么梯度就是
Implementations
那么理论上,在已知正向传播的符号和计算的情况下,计算机可以自动得出反向传播的结果。但是在现代框架中,用户需手动设计局部导数的结算,这也比全自动方式提升了系统的运行效率和稳定性。
class MultiplyGate(object): |
Numeric Gradient Checking
在手动推导和实现反向传播(Backprop)时,这是确保你数学公式没推错、代码没写错的标准验证方法:
- 只需要前向传播函数 即可计算,不需要任何复杂的数学推导,不容易写错。
- 必须对模型的每一个参数分别进行两次前向传播(加 和减 ),效率很低。
- 适合局部测试,不要对整个大型网络做验证,只针对某个特定层或小规模参数(如一个 的矩阵)进行。
Dependency Parsing
Syntactic Structure
- Phrase structure organizes words into nested constituents.
我们可以自己定义phrase构成的语法,比如名词短语可以是“限定词 + 形容词 + 名词”,“限定词 + 名词 + 介词短语”……介词短语可以是“介词 + 名词……”
- Dependency structure shows which words depend on (modify, attach to, or are arguments of) which other words
语言中很容易出现歧义(ambiguity),在英语里有了介词短语,歧义就更多了,举个例子:
“Scientists count whales from space"可以理解为"Scientists [count] [whales from space]” 或者 “Scientists [count whales] [from space]” ……
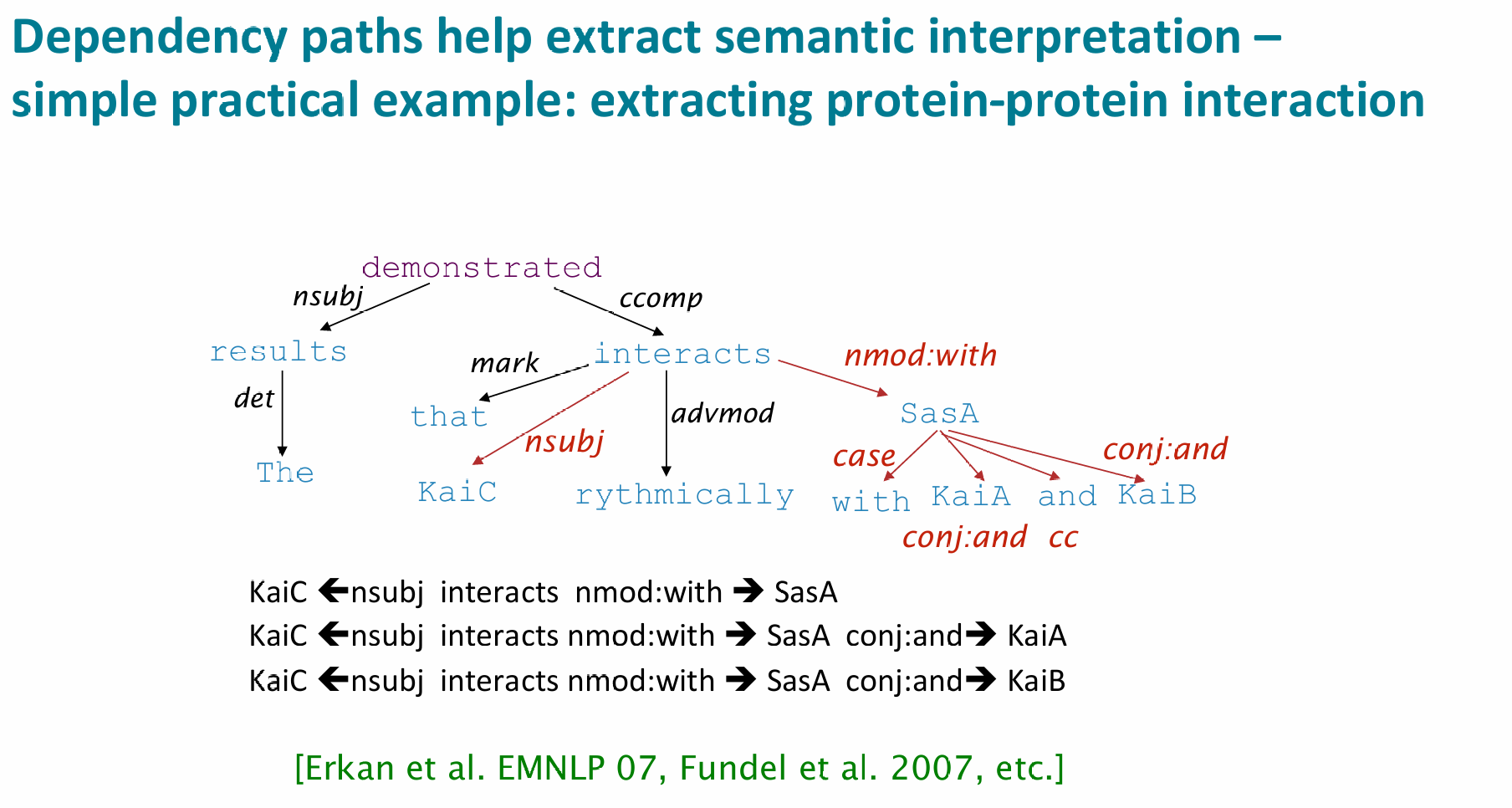
Dependency Grammar and Treebanks
Dependency syntax postulates that syntactic structure consists of relations between
lexical items, normally binary asymmetric relations (“arrows”) called dependencies
下图是个比较古老的"dependency structure"
An arrow connects a head (governor, superior, regent) with a dependent (modifier, inferior, subordinate)
Usually, dependencies form a tree (a connected, acyclic, single-root graph)
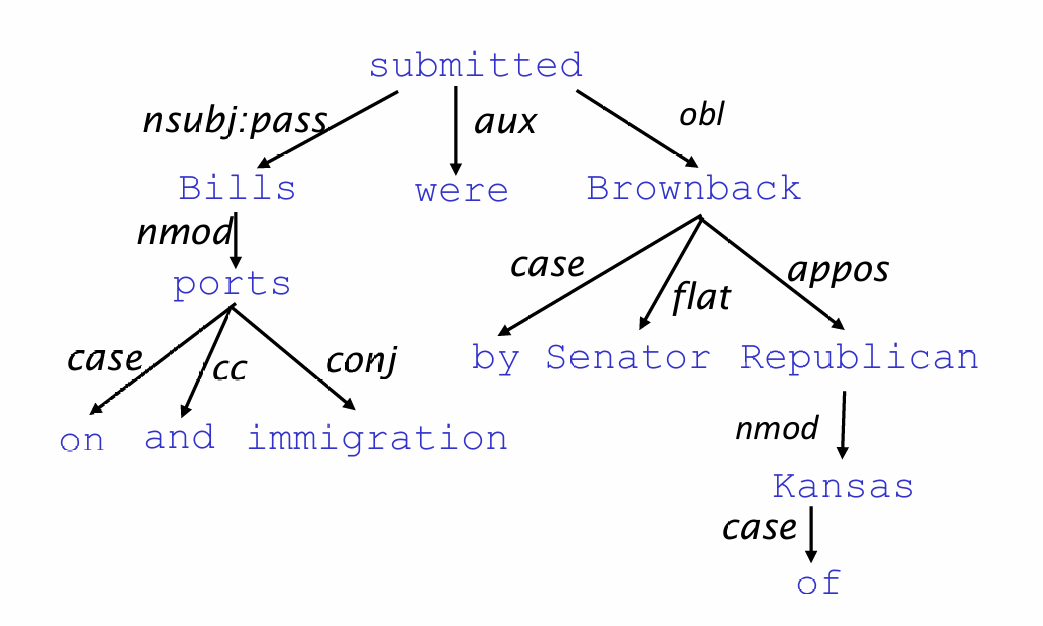
Annotated Data
起初,构建语言库(Treebank)似乎比手动编写语法规则要慢得多,且看起来没那么有用。手动标注数据确实是件麻烦的工作,但现在看来,却有很大的优势:
- 复用性(Reusability):一套标注好的数据可以用来训练多种解析器(Parsers)、词性标注器(POS Taggers)
- 覆盖面广(Board coverage):手动编写规则往往只能覆盖几个直觉上的例子,而标注真实语料可以涵盖语言在现实中的各种复杂用法。
- 频率与分布信息(Frequencies and distributional information):它能告诉机器哪些结构更常见,帮助概率模型做出更准确的判断。
- 评估NLP(A way to evaluate NLP systems):没有这套“标准”,我们就无法衡量一个 AI 模型的准确率(如 LAS/UAS 得分)
那么关于示例图中的各依存关系的意思,如下:
| 缩写 | 意思 | 简单理解 |
|---|---|---|
| nsubj | 名词主语 | 动作的发出者(如 I think) |
| nsubjpass | 被动主语 | 被动语态里的主语(如 city called) |
| ccomp | 从句 | 动词后面的整个小句子(如 think …) |
| advmod | 状语修饰 | 修饰动词的程度、疑问等(如 Why) |
| amod | 形容词修饰 | 修饰名词的形容词(如 famous goat) |
| compound | 复合修饰 | 名词修饰名词(如 goat trainer) |
| det | 限定关系 | 指向 a, the, any 等词 |
| case | 介词关系 | 指向 in, at 等介词 |
| conj | 并列关系 | 用 or, and 连接的词(如 trainer or something) |
Dependency Conditioning Preferences
在进行句法分析时,计算机会根据“依存条件偏好(Dependency Conditioning Preferences)”来判断两个词之间是否存在依存关系:
- 双词亲和力 (Bilexical affinities):依存关系(例如 [discussion → issues])是合理的。
- 依存距离 (Dependency distance):大多数(但并非所有)依存关系发生在邻近的单词之间。
- 介入材料 (Intervening material):依存关系很少跨越中间的动词或标点符号。
- 中心词的价态 (Valency of heads):对于一个中心词(Head)来说,通常在它的哪一侧会有多少个依存词?
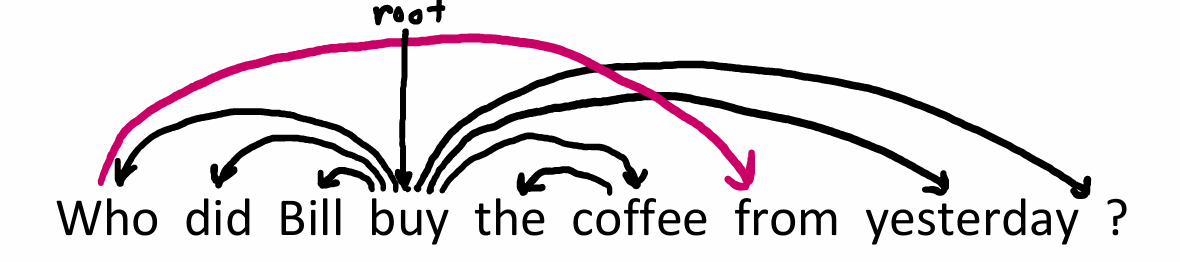
Projectivity
如果一个句子的单词按线性顺序排列,且所有的依存弧(dependency arcs)都画在单词上方时,没有任何两条弧线发生交叉,那么这个解析就是“投影的”。那么互出现了交叉,就是非投影的(non-projectivity),说明发生了“长距离位移”或结构重叠。
但是现实中非投影的例子很常见,比如"Who did Bill buy the coffee from yesterday"
Transition-Based Dependency Parser
首先,这Transition-Based Dependency Parser分有一个Stack和一个Buffer,和三种操作:
Start: $ \sigma = [ROOT], \beta = w_1, …, w_n, A = \emptyset $
-
Shift: $\sigma, w_i | \beta, A \Rightarrow \sigma | w_i, \beta, A $
-
Left-: $\sigma | w_i | w_j, \beta, A \Rightarrow \sigma | w_j, \beta, A \cup {r(w_j, w_i)} $
-
Right-:
Finish:
-
σ(sigma)表示 堆栈(stack),存储当前正在处理或等待建立关系的词。
-
β(beta)表示 缓冲区(buffer),存储尚未处理的输入词序列。
-
A 表示 依存弧集合(set of dependency arcs),存储已建立的依存关系。
-
Left- 和 Right- 是两种规约模型,用来表明一个词是另一个的依存词,以左或右方向。
那么下面先来举个例子:Analysis of “I ate fish”
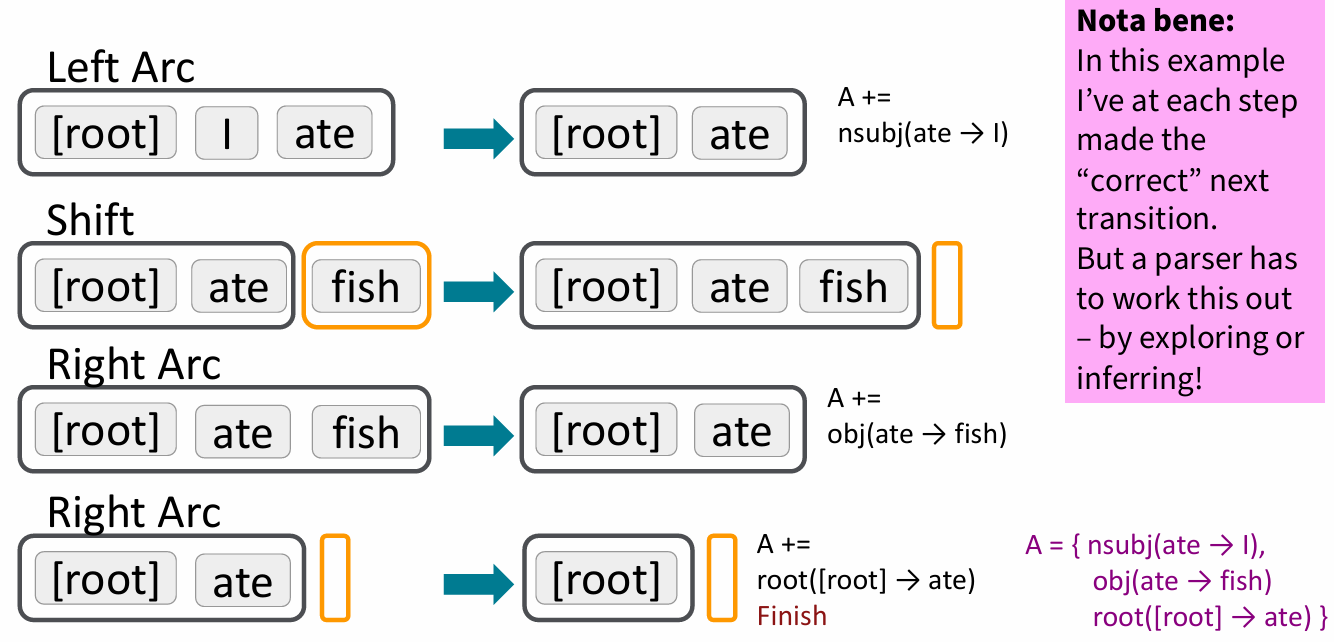
- Left Arc操作 生成了一个由栈顶指向第二个元素的弧,建立了"ate"是中心词,"I"依存于"ate"的关系。然后将"I"移出栈。
- Shift操作 将"fish"从缓冲区移入栈中
- Right Arc操作 生成了一个由第二个元素指向栈顶元素的弧,建立了"ate"是中心词,"fish"依存于"ate"的关系。然后将"fish"移出栈。
- 最后的Right Arc操作 使"[root]“指向"ate”,并在"ate"出栈后,只剩下根节点,操作完成。
Evaluation of Dependency Parsing
评价依存分析的指标分为UAS(无标签附件分数)和 LAS(有标签附件分数),下面是一个具体的例子: “[ROOT] She saw the video lecture.”,表中"Gold"是标准答案,"Parsed"是分析出的答案:
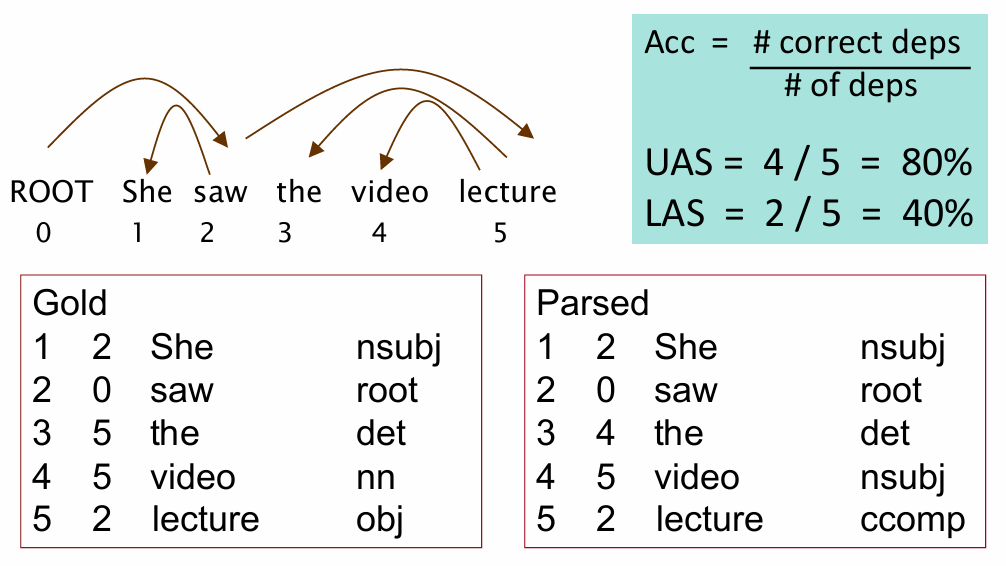
- 可见,UAS计算的是
Head寻找得是否正确,本例中第三个"the"的依存词和标准不符。 - LAS计算的它们之间的关系类型是否标注正确,即
Head和关系标签(label)都要一致,本例中只有"She"和"saw"是与标准相符的。
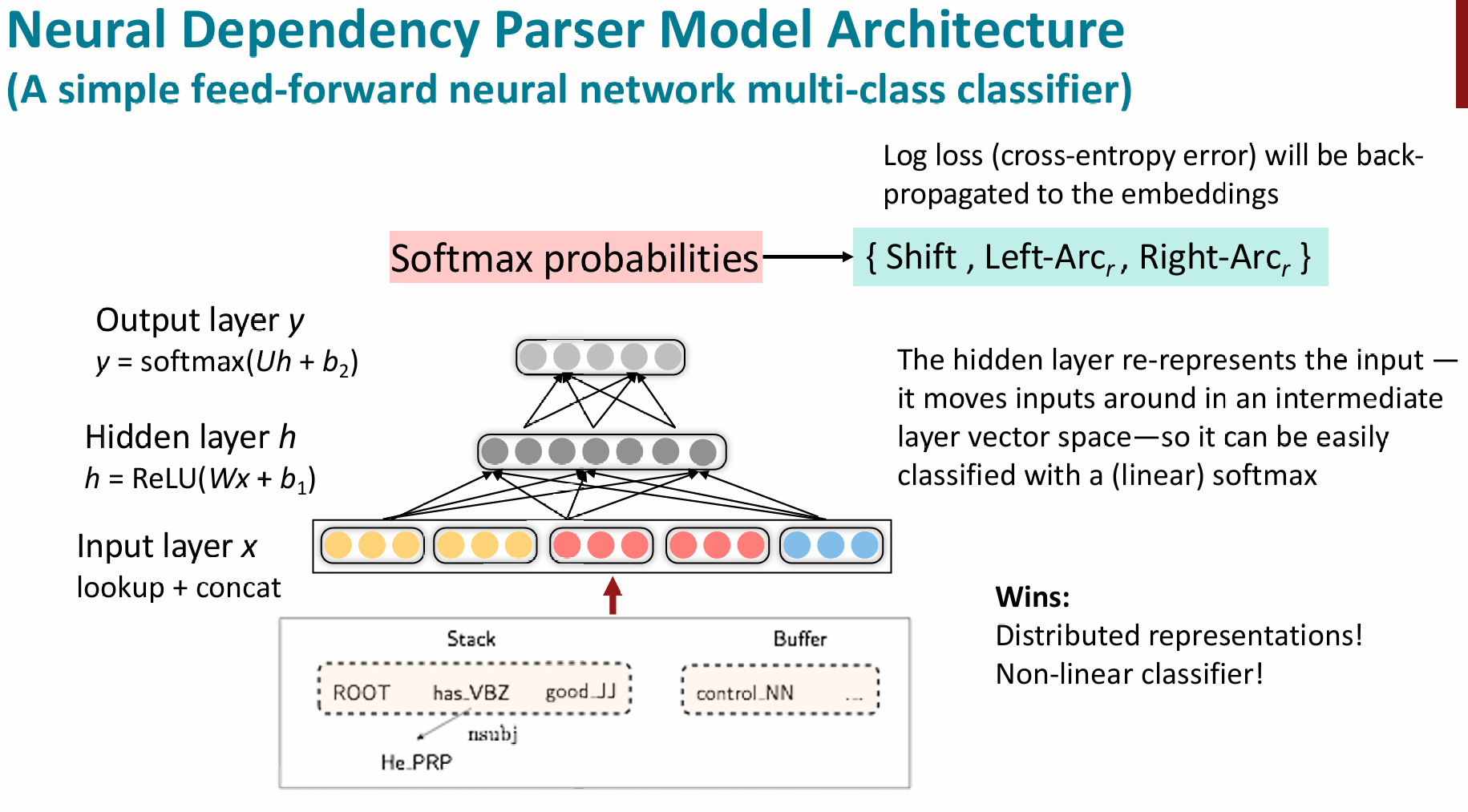
Neural dependency parsing
More than 95% of parsing time is consumed by feature computation
所以,我们可以用神经网络来加速特征提取,当然其方法还是基于上面的基于转移(Transition-based)的神经依存句法分析器。具体使用了了向量化、非线性等深度学习知识搭建出了第一个基于神经网络的依存分析器(2014年)。