CS 224n Spring 2024: Assignment #3
本post从cs224n独立出来,旨在尽可能掌握Assignment3中基于RNN的NMT背后各步的数学原理,以及将代码部分和数学部分对应起来。
参考论文:
NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE
Neural Machine Translation with RNNs
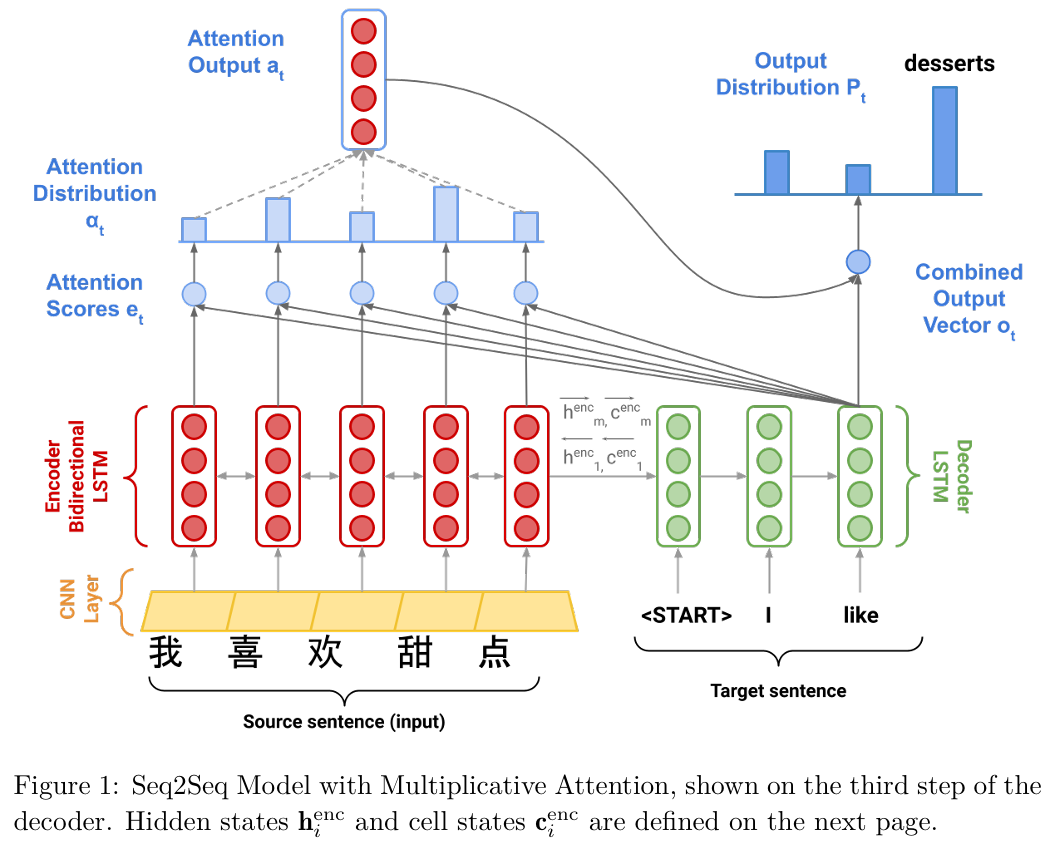
Model description (training procedure)
Given a sentence in the source language, we look up the character or word embeddings from an embeddings matrix, yielding $\mathbf{x}_1, \ldots, \mathbf{x}_m$ ($\mathbf{x}_i \in \mathbb{R}^{e \times 1}$), where $m$ is the length of the source sentence and $e$ is the embedding size.
我们手里的一条源语言句子,由于计算机无法直接理解文字,我们首先要进行“查表”操作,也就是文本中提到的获取词嵌入(look up … embeddings matrix)。假设句子有 $m$ 个词,经过这一步,每个词都被映射成了一个长度为 $e$ 的列向量 $\mathbf{x}_i$。这样一来,整句话就被转换成了一个由实数向量构成的序列
We then feed the embeddings to a convolutional layer$^1$ while maintaining their shapes.
$^1$ : Checkout Convolutional Neural Networks for an in-depth description for convolutional layers if you are not familiar.
带着这些初步的向量表示,模型并没有直接把它们送入主要的编码器,而是先让它们穿过一个卷积层(convolutional layer)。文本中特别强调了这一步“保持了它们的形状”,这意味着经过卷积处理后,我们依然拥有 $m$ 个向量,且每个向量的维度依然是 $e$。这一步的作用通常是对局部的特征进行一次平滑和提取,为后续更深层的语义理解打好基础。
We feed the convolutional layer outputs to the bidirectional encoder, yielding hidden states and cell states for both the forwards ($\rightarrow$) and backwards ($\leftarrow$) LSTMs. The forwards and backwards versions are concatenated to give hidden states $\mathbf{h}_i^{\text{enc}}$ and cell states $\mathbf{c}_i^{\text{enc}}$:
$$ \mathbf{h}_i^{\text{enc}} = [\overleftarrow{\mathbf{h}_i^{\text{enc}}} ; \overrightarrow{\mathbf{h}_i^{\text{enc}}}] \quad \text{where} \quad \mathbf{h}_i^{\text{enc}} \in \mathbb{R}^{2h \times 1}, \overleftarrow{\mathbf{h}_i^{\text{enc}}}, \overrightarrow{\mathbf{h}_i^{\text{enc}}} \in \mathbb{R}^{h \times 1} \quad 1 \leq i \leq m \quad (1) $$$$ \mathbf{c}_i^{\text{enc}} = [\overleftarrow{\mathbf{c}_i^{\text{enc}}} ; \overrightarrow{\mathbf{c}_i^{\text{enc}}}] \quad \text{where} \quad \mathbf{c}_i^{\text{enc}} \in \mathbb{R}^{2h \times 1}, \overleftarrow{\mathbf{c}_i^{\text{enc}}}, \overrightarrow{\mathbf{c}_i^{\text{enc}}} \in \mathbb{R}^{h \times 1} \quad 1 \leq i \leq m \quad (2) $$接下来,这些被初步加工过的特征向量正式进入了核心组件——双向编码器(bidirectional encoder)。这里其实包含了两条流水线:一条是前向 LSTM(在数学符号中用向右的箭头 $\rightarrow$ 表示),它顺着我们阅读的习惯,从第一个词读到最后一个词,负责收集每个词左侧的“上文”信息;另一条是后向 LSTM(用向左的箭头 $\leftarrow$ 表示),它逆着顺序,从最后一个词倒着读回来,负责收集每个词右侧的“下文”信息。当这两条流水线各自运转完毕后,对于句子中的任意第 $i$ 个位置,我们就得到了两个不同视角的隐藏状态 $\mathbf{h}_i^{\text{enc}}$ 和细胞状态 $\mathbf{c}_i^{\text{enc}}$,前向( $\overrightarrow{\mathbf{h}_i^{\text{enc}}}$ , $\overrightarrow{\mathbf{c}_i^{\text{enc}}}$ )或后向( $\overleftarrow{\mathbf{h}_i^{\text{enc}}}$ , $\overleftarrow{\mathbf{c}_i^{\text{enc}}}$ )分别的状态量,维度都是 $h \times 1$ 。
$[ ; ]$ 在线性代数中通常表示向量或矩阵的拼接。为了让第 $i$ 个位置最终的表示既包含左侧上下文,又包含右侧上下文,模型将同一时刻 $i$ 的前向状态和后向状态直接“拼接”在一起。因为前向和后向状态都是 $h \times 1$ 的列向量,将它们沿行方向拼接后,最终的联合隐藏状态 $\mathbf{h}_i^{\text{enc}}$ 和联合细胞状态 $\mathbf{c}_i^{\text{enc}}$ 的维度就翻倍了,变成了 $(h+h) \times 1 = \mathbf{2h \times 1}$。
We then initialize the decoder’s first hidden state $\mathbf{h}_0^{\text{dec}}$ and cell state $\mathbf{c}_0^{\text{dec}}$ with a linear projection of the encoder’s final hidden state and final cell state.$^2$
$^2$ : If it’s not obvious, think about why we regard $[\overleftarrow{\mathbf{h}_1^{\text{enc}}} , \overrightarrow{\mathbf{h}_m^{\text{enc}}}]$ as the ‘final hidden state’ of the Encoder.
$$ \mathbf{h}_0^{\text{dec}} = \mathbf{W}_h [\overleftarrow{\mathbf{h}_1^{\text{enc}}} ; \overrightarrow{\mathbf{h}_m^{\text{enc}}}] \quad \text{where} \quad \mathbf{h}_0^{\text{dec}} \in \mathbb{R}^{h \times 1}, \mathbf{W}_h \in \mathbb{R}^{h \times 2h} \quad (3) $$$$ \mathbf{c}_0^{\text{dec}} = \mathbf{W}_c [\overleftarrow{\mathbf{c}_1^{\text{enc}}} ; \overrightarrow{\mathbf{c}_m^{\text{enc}}}] \quad \text{where} \quad \mathbf{c}_0^{\text{dec}} \in \mathbb{R}^{h \times 1}, \mathbf{W}_c \in \mathbb{R}^{h \times 2h} \quad (4) $$双向编码器(Encoder)已经工作完毕,看完了整句源语言文本,并在每一个位置都留下了浓缩的上下文信息。接下来的任务就是把这些信息传递给解码器(Decoder),让它开始生成翻译。传递的过程就是通过下面公式中,初始化解码器在第0步的隐藏状态 $\mathbf{h}_0^{\text{dec}}$ 和细胞状态 $\mathbf{c}_0^{\text{dec}}$ 来完成的。解码器的初始状态是从编码器那里继承来的“最终状态”。
编码器在“读完”整句话后的最终状态,可见公式:前向 LSTM 是顺着语序从左到右读的,所以当它读完最后一个词时,它的最终状态自然就落在了句尾,也就是第 $m$ 个位置,记作 $\overrightarrow{\mathbf{h}_m^{\text{enc}}}$。相反,后向 LSTM 是倒着从右向左读的,它“通读全文”后的最后一站其实是句子的开头,也就是第 $1$ 个位置,记作 $\overleftarrow{\mathbf{h}_1^{\text{enc}}}$。
为了把前向和后向这两股贯穿全文的“记忆”汇聚起来,我们按照公式将它们进行了拼接操作 $[\overleftarrow{\mathbf{h}_1^{\text{enc}}} ; \overrightarrow{\mathbf{h}_m^{\text{enc}}}]$。(需注意,在Decoder这一步和公式 (1) (2) 的上下文状态量不一样)
通过这个拼接,我们得到了一个维度为 $2h \times 1$ 的长向量。同样地,对于细胞状态 $\mathbf{c}$,我们用完全相同的逻辑提取出 $[\overleftarrow{\mathbf{c}_1^{\text{enc}}} ; \overrightarrow{\mathbf{c}_m^{\text{enc}}}]$。那么对于 $2h \times 1$ 的向量,我们要将其转换成 $h\times 1$ 才能满足解码器的隐藏层容量。
所以引入权重(投影)矩阵,用来做线性投影(linear projection),维度是 $h \times 2h$ ,再通过矩阵相乘,映射出 $h\times 1$ 的向量。
With the decoder initialized, we must now feed it a target sentence.
成功初始化了解码器的第 0 步状态($\mathbf{h}_0^{\text{dec}}$ 和 $\mathbf{c}_0^{\text{dec}}$)之后。现在,解码器已经准备好生成(或在训练时接收)目标语言的句子了。下面内容讲的就是在任意的第 $t$ 步,解码器是如何“吃进”数据并更新自己状态的。
On the $t^{th}$ step, we look up the embedding for the $t^{th}$ subword, $\mathbf{y}_t \in \mathbb{R}^{e \times 1}$.
要让解码器在第 $t$ 步进行工作,我们首先得给它提供当前的输入词,同样需要查表,把目标语言的第 $t$ 个子词(subword)变成一个维度为 $e$ 的词嵌入向量,记作 $\mathbf{y}_t$。
We then concatenate $\mathbf{y}t$ with the combined-output vector $\mathbf{o}{t-1} \in \mathbb{R}^{h \times 1}$ from the previous timestep (we will explain what this is later down this page!) to produce $\overline{\mathbf{y}_t} \in \mathbb{R}^{(e+h) \times 1}$.
但是,如果只把 $\mathbf{y}_t$ 喂给解码器,它会缺乏连贯性。为了让解码器知道“我刚才干了什么”,文本中引入了一个非常关键的设计:把当前的词向量 $\mathbf{y}t$ 与上一步(第 $t-1$ 步)的维度为 $h$ 的联合输出向量 (combined-output vector) $\mathbf{o}{t-1}$ 拼接在一起,得到新的输入向量 $\overline{\mathbf{y}_t}$,它的维度变成了 $e+h$。
Note that for the first target subword (i.e. the start token) $\mathbf{o}_0$ is a zero-vector. We then feed $\overline{\mathbf{y}_t}$ as input to the decoder.
$$ \mathbf{h}_t^{\text{dec}}, \mathbf{c}_t^{\text{dec}} = \text{Decoder}(\overline{\mathbf{y}_t}, \mathbf{h}_{t-1}^{\text{dec}}, \mathbf{c}_{t-1}^{\text{dec}}) \quad \text{where} \quad \mathbf{h}_t^{\text{dec}} \in \mathbb{R}^{h \times 1}, \mathbf{c}_t^{\text{dec}} \in \mathbb{R}^{h \times 1} \quad (5) $$注意到当 $t=1$ ,也就是解码器刚开始吐出第一个词(或者接收 start token)时,因为前面还没有任何输出,所以初始的 $\mathbf{o}_0$ 就简单地设定为一个全零向量。
关于向Decoder中输入了三个变量后,在LSTM的Decoder里进行了什么计算,需结合CS224N中LSTM的部分进行理解:(generated by Gemini)
- 遗忘门 (Forget Gate)
- 参与者: 新输入 $\overline{\mathbf{y}t}$ 和旧的短期记忆 $\mathbf{h}{t-1}^{\text{dec}}$。
- 动作: 把这两个变量拼接在一起,乘上一个权重矩阵,加上偏置,然后送入一个 Sigmoid 激活函数。
- 产出: 得到一个介于 0 到 1 之间的向量 $f_t$。
- 意义: 这个 $f_t$ 会盯着传送带上的旧长期记忆 $\mathbf{c}_{t-1}^{\text{dec}}$ 看。0 代表“彻底忘掉”,1 代表“完全保留”。比如遇到新的主语,它可能就会决定忘掉旧主语的单复数信息。
- 输入门与候选记忆 (Input Gate & Candidate Memory)
- 参与者: 依然是 $\overline{\mathbf{y}t}$ 和 $\mathbf{h}{t-1}^{\text{dec}}$。
- 动作: 这里分两头行动:
- 输入门 $i_t$: 再次经过一个 Sigmoid 函数,产生 0 到 1 的值,决定我们有多希望把新信息存进去。
- 候选记忆 $\tilde{\mathbf{c}}_t$: 经过一个 tanh 激活函数,产生 -1 到 1 的值,这代表从当前输入中提取出的全部潜在新知识。
- 意义: 这两步结合,就是要把提炼出的新知识($\tilde{\mathbf{c}}_t$)按照我们的渴望程度($i_t$)进行打包,准备放到传送带上。
- 状态更新 (Cell State Update)
- 参与者: 旧记忆 $\mathbf{c}_{t-1}^{\text{dec}}$,遗忘门 $f_t$,输入门 $i_t$,候选记忆 $\tilde{\mathbf{c}}_t$。
- 动作: 纯粹的数学运算。首先用旧记忆乘以遗忘门:$f_t * \mathbf{c}_{t-1}^{\text{dec}}$ (执行“丢弃”动作);然后加上新的包裹:$i_t * \tilde{\mathbf{c}}_t$ (执行“装载”动作)。
- 产出: 我们得到了当前时刻的全新细胞状态 $\mathbf{c}_t^{\text{dec}}$。
- 意义: 长期记忆的传送带在这里完成了向前推进,旧的糟粕被剔除,新的信息被注入。这就是 LSTM 能够跨越长距离保持梯度的核心。
- 输出门与隐藏状态 (Output Gate & Hidden State)
- 参与者: $\overline{\mathbf{y}t}$,$\mathbf{h}{t-1}^{\text{dec}}$,以及刚刚出炉的新细胞状态 $\mathbf{c}_t^{\text{dec}}$。
- 动作:
- 用 $\overline{\mathbf{y}t}$ 和 $\mathbf{h}{t-1}^{\text{dec}}$ 经过 Sigmoid 算出一个输出门 $o_t$(决定展示的比例)。
- 把刚刚做好的新细胞状态 $\mathbf{c}_t^{\text{dec}}$ 用 tanh 函数“压”到 -1 到 1 之间。
- 两者相乘:$\mathbf{h}_t^{\text{dec}} = o_t * \tanh(\mathbf{c}_t^{\text{dec}})$。
- 产出: 我们得到了当前时刻的全新隐藏状态 $\mathbf{h}_t^{\text{dec}}$。
- 意义: 细胞状态 $\mathbf{c}_t$ 包含的信息太庞杂了(有些可能是给未来留的伏笔),我们不能全部暴露。输出门 $o_t$ 就像一个滤网,只把当前这一步预测下一个词最需要的那部分特征提取出来,作为对外的公开展示($\mathbf{h}_t$)。
We then use $\mathbf{h}_t^{\text{dec}}$ to compute multiplicative attention over $\mathbf{h}_1^{\text{enc}}, \dots, \mathbf{h}m^{\text{enc}}$: $$ \mathbf{e}_{t,i} = (\mathbf{h}_t^{\text{dec}})^T \mathbf{W}_{\text{attProj}} \mathbf{h}_i^{\text{enc}} \quad \text{where} \quad \mathbf{e}_t \in \mathbb{R}^{m \times 1}, \mathbf{W}_{\text{attProj}} \in \mathbb{R}^{h \times 2h} \quad 1 \leq i \leq m \quad (6) $$ $\mathbf{e}{t,i}$ is a scalar, the $i$ th element of $\mathbf{e}_t \in \mathbb{R}^{m \times 1}$, computed using the hidden state of the decoder at the $t$ th step, $\mathbf{h}t^{\text{dec}} \in \mathbb{R}^{h \times 1}$, the attention projection $\mathbf{W}{\text{attProj}} \in \mathbb{R}^{h \times 2h}$, and the hidden state of the encoder at the $i$ th step, $\mathbf{h}_i^{\text{enc}} \in \mathbb{R}^{2h \times 1}$.
$$ \alpha_t = \text{softmax}(\mathbf{e}_t) \quad \text{where} \quad \alpha_t \in \mathbb{R}^{m \times 1} \quad (7) $$公式(6)是注意力机制的Scoring,解码器现在的状态是 $\mathbf{h}_t^{\text{dec}}$,它需要和字典里的每一个词 $\mathbf{h}_i^{\text{enc}}$进行比对,看看有多匹配。
$(\mathbf{h}t^{\text{dec}})^T$ , $\mathbf{W}{\text{attProj}}$ , $\mathbf{h}i^{\text{enc}}$ 这三者相乘后维度为 $1\times 1$ ,即Scoring出的标量 $\mathbf{e}{t,i}$ ,它代表了在生成第 $t$ 个翻译词时,源语言句子中第 $i$ 个词的重要程度。 我们把对所有 $m$ 个词的打分收集起来,就得到了一个长度为 $m$ 的得分向量 $\mathbf{e}_t$ 。
$$ \mathbf{a}_t = \sum_{i=1}^m \alpha_{t,i} \mathbf{h}_i^{\text{enc}} \quad \text{where} \quad \mathbf{a}_t \in \mathbb{R}^{2h \times 1} \quad (8) $$为了把公式 (6) 的得分变成标准的“注意力分配比例”,公式 (7) 引入了
softmax函数。它把向量 $\mathbf{e}_t$ 里的所有数字全部转换为 $0$ 到 $1$ 之间的正数,并且保证它们的总和严格等于 $1$。转换后的结果就是 $\alpha_t$(被称为注意力分布 Attention Distribution)。
公式 (8) 用刚算出来的注意力百分比 $\alpha_{t,i}$,去对字典里的词 $\mathbf{h}_i^{\text{enc}}$ 进行加权求和。把这 $m$ 个按比例缩放的向量全部加起来,我们就得到了最终的注意力输出向量(Attention Output / Context Vector),记作 $\mathbf{a}_t$。 由于被加和的 $\mathbf{h}_i^{\text{enc}}$ 都是 $2h \times 1$ 维的,所以最终得到的 $\mathbf{a}_t$ 也是 $2h \times 1$ 维。
We now concatenate the attention output $\mathbf{a}_t$ with the decoder hidden state $\mathbf{h}_t^{\text{dec}}$ and pass this through a linear layer, tanh, and dropout to attain the combined-output vector $\mathbf{o}_t$.
$$ \mathbf{u}_t = [\mathbf{a}_t ; \mathbf{h}_t^{\text{dec}}] \quad \text{where} \quad \mathbf{u}_t \in \mathbb{R}^{3h \times 1} \quad (9) $$$$ \mathbf{v}_t = \mathbf{W}_u \mathbf{u}_t \quad \text{where} \quad \mathbf{v}_t \in \mathbb{R}^{h \times 1}, \mathbf{W}_u \in \mathbb{R}^{h \times 3h} \quad (10) $$将注意力输出向量和解码器隐藏状态结合,得到维度为 $3h\times 1$ 的 $u_t$
$$ \mathbf{o}_t = \text{dropout}(\tanh(\mathbf{v}_t)) \quad \text{where} \quad \mathbf{o}_t \in \mathbb{R}^{h \times 1} \quad (11) $$加入了一个线性投影矩阵 $\mathbf{W}_u$(维度是 $h \times 3h$ ,当它和 $\mathbf{u}_t$ 相乘时,把维度压缩回了标准尺寸 $h \times 1$
首先给它套上一个
tanh激活函数,将其内部的数值平滑地压缩到 -1 到 1 之间,这赋予了模型非线性的表达能力。紧接着,再让它穿过一层dropout。dropout是一种防止模型过拟合的正则化技术,它在训练时会随机屏蔽掉一部分神经元,逼迫模型学到更鲁棒、更泛化的特征。最后得到联合输出向量(combined-output vector) $\mathbf{o}_t$
Then, we produce a probability distribution $\mathbf{P}_t$ over target subwords at the $t^{th}$ timestep:
$$ \mathbf{P}_t = \text{softmax}(\mathbf{W}_{\text{vocab}}\mathbf{o}_t) \quad \text{where} \quad \mathbf{P}_t \in \mathbb{R}^{V_t \times 1}, \mathbf{W}_{\text{vocab}} \in \mathbb{R}^{V_t \times h} \quad (12) $$我们要把一个 $h$ 维的向量,变成目标语言词典里的一个具体词汇。我们的目标语言词典(Vocabulary)里一共有 $V_t$ 个单词。公式 (12) 引入了一个最终的变换矩阵 $\mathbf{W}_{\text{vocab}}$,它的维度是 $V_t \times h$。相乘后输出一个 $[V_t \times 1]$ 的列向量。这个向量里的每一个数字,就代表了模型对词典里对应单词的“打分”(Logits)。
Here, $V_t$ is the size of the target vocabulary. Finally, to train the network we then compute the cross entropy loss between $\mathbf{P}_t$ and $\mathbf{g}_t$, where $\mathbf{g}_t$ is the one-hot vector of the target subword at timestep $t$:
$$ J_t(\theta) = \text{CrossEntropy}(\mathbf{P}_t, \mathbf{g}_t) \quad (13) $$训练过程使用了交叉熵损失 (Cross Entropy Loss) 函数。简单来说,交叉熵会去对比 $\mathbf{P}_t$ 和 $\mathbf{g}_t$ (one-hot vector)之间的差距。计算出损失 $J_t(\theta)$ 之后,在接下来的代码实现中,模型就会利用反向传播机制,顺着网络一路往回找,去微调那些导致错误的参数 $\theta$。
Setting up Cloud GPU-powered Virtual Machine
Implementation and written questions
在问题 (c) 的nmt_model.py的__inti__()中,关于神经网络各层的定义,其中self.att_projection的定义需注意,虽然它对应的是 $W_{attProj}$ ,但是在编写代码时,要拆解结合律,决定计算顺序。
应该先算$\mathbf{W}_{\text{attProj}} $ 和 $\mathbf{h}_i^{\text{enc}}$ 相乘,再将其乘积与 $(\mathbf{h}_t^{dec})^T$ 相乘求最终结果,这是因为所有的编码器状态 $\mathbf{h}_i^{\text{enc}}$ 在 Decoder 开始工作前就已经全部计算好了。你可以一次性把整句话的 $\mathbf{h}^{\text{enc}}$ 丢进 Linear 层进行投影(这叫 Pre-computation 预计算)。但是在某一时刻只有一个 $\mathbf{h}_t^{dec}$ 而没有未来的量,导致不能一次性投影完成,而只能把线性层放到了循环中,引发严重的性能问题(虽然数学原理上没错)。下面是一个例子(generated by Gemini) :
假设我们的模型参数如下:
- 隐藏层大小 $h = 512$
- 句子长度 $m = 50$
把
Linear层塞进循环里在这个路线里,
Linear层每次要干的活是:把解码器 $1 \times 512$ 的向量,乘以一个 $512 \times 1024$ 的巨大投影矩阵 $\mathbf{W}$。
- 计算量:这需要进行 $512 \times 1024 = \mathbf{524,288}$ 次乘加运算!
- 额外开销:每次循环,PyTorch 都要去内存里把这个包含 50 多万个参数的 $\mathbf{W}$ 矩阵重新搬出来读一遍,并且要经过一层完整的
nn.Linear封装代码(包含各种维度检查、梯度跟踪的准备)。然后,算出投影结果后,还得再去和字典做点积:$1 \times 1024$ 的向量乘以 $1024 \times 50$ 的字典,又是 $\mathbf{51,200}$ 次运算。
所以在这个路线下,解码器每走一步,都要背着将近 60万次运算 和一个巨大的矩阵跑。
预计算 + 循环内纯点积
我们把庞大的
Linear投影放在循环外面,利用 GPU 的超级并行能力,**“一瞬间”**把整本字典从 $50 \times 1024$ 压成了 $50 \times 512$。我们把这本新字典称为 “投影后字典”。现在我们进入了
for循环。在第 $t$ 步,我们需要做的乘法是什么呢?
- 计算量:我们直接拿解码器原生的 $1 \times 512$ 向量,去乘以准备好的“投影后字典”($512 \times 50$)。只需要进行 $512 \times 50 = \mathbf{25,600}$ 次乘加运算!
- 没有额外的层开销:这里不需要调用
nn.Linear,我们在代码里只要写一个极其轻量的纯矩阵乘法指令(比如torch.matmul或@符号)就搞定了。不需要加载任何权重矩阵,因为权重矩阵的任务在循环外已经完成了!
问题 (d) 是encoder部分,以及对decoder部分的初始化:
| |
self.model_embeddings是对ModelEmbeddings的一个实例化,而回到问题 (a) 发现.source是一个nn.Embedding对象:
| |
但是在问题 (a) 中只是对它的实例化,在内存中申请了一个形状为 (num_embeddings, embedding_dim) 的大矩阵。
| |
又因为 nn.Embedding 继承自 nn.Module,而 nn.Module 重写了 __call__ 方法,所以你可以像函数一样使用它(调用),参数设为source_padded这样一个Tensor,它把 Tensor 里的每一个数字当成“行号”,去刚才创建的那个大矩阵里把对应的行找出来,然后输出包含词向量的 Tensor。
下面在将Tensor送进Encoder之前,要用torch.permute变换形状,从(src_len, b, e)变到(b, e, src_len)。那么torch.permute的参数,只是参数位置(索引号)。如下,将原来索引为1的b放到第0个位置,原来索引为2的放到第1个位置,原来索引为0的放到第2个位置。
| |
之后将Tensor X送进LSTM的Encoder后,得到输出:
| |
output对应的就是双向LSTM的全局上下文向量: $\mathbf{h}_1^{\text{enc}}, \ldots, \mathbf{h}_m^{\text{enc}}$
last_hidden对应的是:$\overrightarrow{\mathbf{h}_m^{\text{enc}}}$ 和 $\overleftarrow{\mathbf{h}_1^{\text{enc}}}$ ,它的形状是 (num_layers * num_directions, batch_size, hidden_size) ,由于它是双向的,所以索引0和索引1分别对应,我们需要将其分离再拼接,形成我们需要的$\overleftarrow{\mathbf{h}_1^{\text{enc}}} ; \overrightarrow{\mathbf{h}_m^{\text{enc}}}$ 。注意torch.cat的参数dim=1表示为横向拼接,即拼接好的向量的列数变成了2 * hidden_size
与投影矩阵相乘的部分,由实例化好的线性层self.h_projection完成。
| |
last_cell同理,不再赘述。